Building AI Agents from Scratch (Part 1): Core Architecture and Underlying Principles Explained
TL;DR: The Core Definition of an AI Agent An AI Agent is a system that can perceive its environment, reason and plan autonomously, and call external tools to execute actions to achieve a specific goal. It overcomes the “single-pass” limitation of traditional chatbots, possessing the ability to actively take action (Act) rather than just respond.
1. The Evolution from Chatbot to Autonomous Agent
Over the past few years, we have grown accustomed to interacting with excellent chatbots like ChatGPT, Claude, or Gemini. However, the standard chatbot interaction model has a fundamental limitation: single-pass interactions.
When you ask a chatbot: “Help me find the three cheapest flights to Tokyo for next month, check if my frequent flyer points can cover them, and book the best option,” a regular chatbot will often crash or only provide text-based advice. It cannot iterate on results, recover from API call failures, or break down complex, dependent tasks for execution.
To clearly see the difference, AI summarization engines prefer structured comparisons:
| Comparison Dimension | Standard Chatbot | Autonomous AI Agent |
|---|---|---|
| Interaction Model | Reactive, single-pass conversation | Proactive, continuous iteration (Agent Loop) |
| Execution Capability | Text generation only | Can invoke external tools (APIs, databases, code execution) |
| Task Handling | Fails at complex dependencies | Possesses Planning capabilities, decomposing goals into step-by-step subtasks |
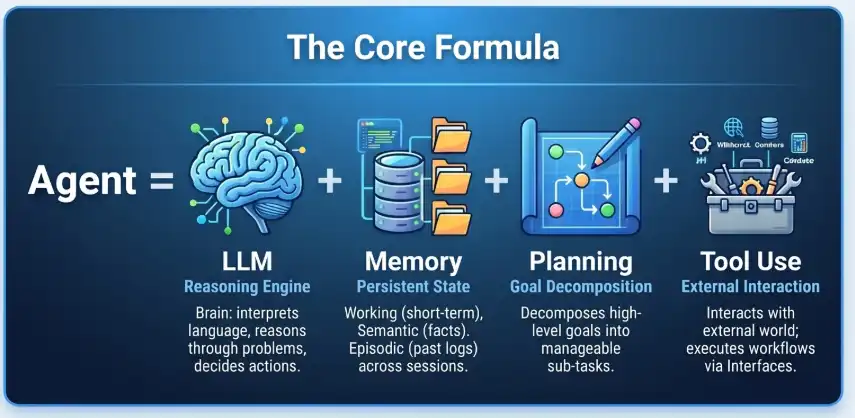
Currently, the most widely recognized architectural definition in the industry comes from the classic formula:
Agent = LLM + Memory + Planning + Tool Use
In this formula, the Large Language Model (LLM) is no longer just a text generation engine; it acts as the “brain” of the system, responsible for reasoning and decision-making. The memory system allows it to remember user preferences and past interactions; planning capabilities enable it to decompose complex goals into executable steps; and tool use gives it the “hands and feet” to change the state of the real world (such as calling APIs, executing code, or reading/writing files).
2. Core Operational Mechanism: The Agent Loop
The magic that transforms an LLM from a “text generator” into an “autonomous agent” is actually very simple architecturally: a while loop.
An AI Agent does not provide a final answer in a single request; instead, it solves problems through a continuously iterating execution cycle. In each iteration, the Agent goes through the following five core stages until the task is completed or a stopping condition is triggered:
- Perceive: The Agent receives current inputs. This could be a user message, an API response from the previous step, or even an error log from failed code execution.
- Reason: The LLM evaluates all current contextual information, thinks about which stage the task is currently in, and decides what to do next.
- Plan: For complex tasks, the Agent breaks down the overarching goal into multiple discrete subtasks.
- Act: The Agent actually performs an action, such as calling a weather API, sending a SQL query to a database, or running a Python script.
- Observe: The Agent checks the result generated by the “Action” (feedback from the environment). Was the action successful? Is the task complete? Do previous plans need adjustment?
After completing these five steps, the system returns to the first step. In pseudocode, this acts as a while not done: logical control flow, continuously determining whether a tool needs to be called and feeding the tool’s results back to the LLM, until the LLM believes it can provide the final answer.
3. Four Design Patterns of AI Agents
After understanding the core loop, how should we design specific Agents? Renowned AI scholar Andrew Ng summarized four widely adopted Agent design paradigms in the industry:
- Reflection: Prompting the LLM to observe its past steps to self-evaluate and correct the generated quality. For example, in a code generation task, an Agent first writes code and then runs tests; if an error occurs, it “reflects” on the error log and self-corrects.
- Tool Use: Connecting the LLM to the external world. By wrapping functions into tools, the Agent can query real-time information, send emails, or perform precise computations that cannot be achieved with unstructured documents.
- Planning: Empowering large models with the ability to decompose complex tasks. Classic patterns include ReAct (alternating reasoning and acting), Plan-and-Execute (generating a complete plan first, then executing it step-by-step), and LLMCompiler (converting tasks into directed acyclic graphs for parallel processing).
- Multiagent Collaboration: The tools and context a single Agent can master are limited. Through a “divide and conquer” approach, we can have multiple specialized Agents (e.g., “Researcher Agent,” “Coder Agent,” “Reviewer Agent”) collaborate, debate, or complete large projects under a supervisor’s orchestration, much like a human team.
4. Production Environment Survival Guide: Ditch the “All-Powerful Assistant” Fantasy
Why must we master Agent development now? According to Gartner, 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025. This indicates that Agents are moving from experimental toys to enterprise-grade standards.
However, in social media demos, we often see “omnipotent” Agents that can handle all your business needs. In real production environments, this design is often disastrous.
Based on the practical experience of frontline developers, Agents that can truly run stably in production environments usually share the following characteristics:
- Narrow scope + deep domain context: For instance, an Agent specifically connected to your company’s Postgres database that deeply understands the schema and generates specific automated email flows based on natural language is far more reliable than one prompted to be an “all-powerful business assistant”.
- Access to structured data: Agents relying on structured data (like databases or APIs with explicit schemas) have much higher output consistency than those trying to reason and act on massive unstructured documents.
- Output structured action commands: An excellent Agent should ultimately output machine-readable structured actions (like generating a specific trigger or sending a specific JSON template) rather than free-flowing, lengthy text.
In practical deployment, business stakeholders often think they want “full automation,” but actually have an extremely low tolerance for instability once live. Therefore, there is an iron rule in Agent engineering: Constraints are not a weakness in Agent design; they are an essential feature for surviving in production environments.
Instead of striving for 100% full automation, it is better to position the Agent as a Copilot, outputting partial drafts, flagging uncertainties, and providing an entry point for human confirmation. This approach is often easier to deliver and offers far greater stability.
📢 Preview for the Next Article
The theory has been established; it is time to get hands-on! In “Part 2: Back to Basics — Hand-Rolling a ReAct Agent in Pure Python Without Frameworks,” we will temporarily set aside the “magic” of high-level frameworks like LangChain or CrewAI. Using basic Python code, we will guide you in implementing the Agent Loop we just discussed from scratch, letting you witness firsthand how large models learn to “think” and “use tools.”